
吴恩达机器学习第12天
15-1问题动机
异常检测anomaly detection密度估计
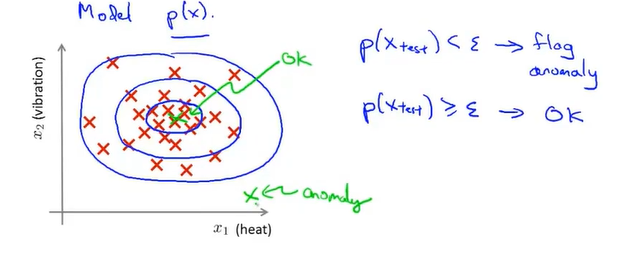
感觉有点像高斯分布的3sigma法则……
建一个模型p(X)
若p(x)小于某个阈值则判断为异常
15-2高斯分布
15-3算法
假设各变量之间独立,所以有
$$P(X) = P(X_1;\mu,\sigma_1^2)P(X_2;\mu,\sigma_2^2) \dots P(X_n;\mu,\sigma_n^2) = \prod_{j=1}^n{P(X_j;\mu_j,\sigma^2_j)}$$
即使不独立用这个代码也可以算出较好的答案
步骤
1.选择合适的特征$x_i$
2.参数拟合$\mu,\sigma^2$
3.给一个新的样本x,计算p(x)
4.判断是否异常(小于阈值)

15-4开发和评估异常检测系统
开发一个评估系统,决定是否纳入一个新的特征。
1. 假设你有一些标签样本,标明哪个是异常哪个是正常
2. 正常的训练集
3. 交叉集和测试集
假设你有10000个正常数据和20个异常数据,分配如下

算法评估
评估标准:
-真假阴阳性
-召回率和命中率
-F1-score
还有p(x)的阈值epslion
15-5异常检测VS监督学习
$$
\begin{array}{l|l}
{异常检测}&{监督学习}\\
\hline
{非常少的正样本,常常是0-20个}&{很大数量的正样本和负样本}\\
{大量的负样本}\\
{如果有多种类的异常,很难从正样本看出是哪种异常}&{}\\
{很难预测出未在正样本中出现的异常}&{有足够的正样本去预测是何种异常和未知异常}\\
\end{array}
$$
所以如果使用异常检测的时候需要用大量的负样本来保证算法能够学到足够多的知识
从应用上
$$
\begin{array}{l|l}
{异常检测}&{监督学习}\\
\hline
{欺骗检测}&{邮件分类}\\
{工业生产}&{天气预测}\\
{数据监测机器}&{癌症分类}\\
\end{array}
$$
如果异常样本较少,则使用异常检测,如果正负样本都很多,则用监督学习。
15-6选择要使用的功能
非高斯特征尝试转换为高斯特征。
取对数变换、开根号变换
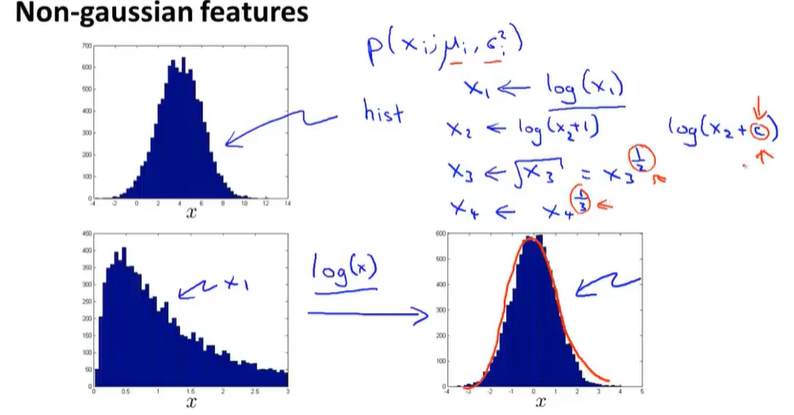
话说取什么函数要一个一个试吗=.=
异常检测的误差分析
尝试创建一个新特征,给异常样本较低的概率
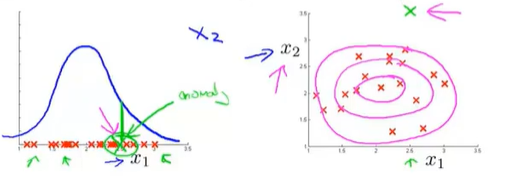
通过特征间关系组合出一个新的特征,来更好的监测某个错误。
15-7多变量高斯分布
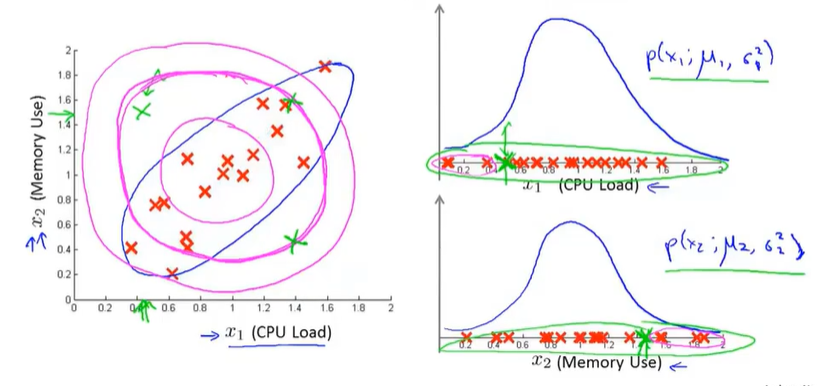
为了解决某些不符合常规数据,但是却在单个特征的高斯分布中占大概率的情况。

协方差矩阵的影响
以下是对2*2的协方差矩阵而言
左上角元素决定在x1方向上的缩放率
右下角元素决定在x2方向上的缩放率
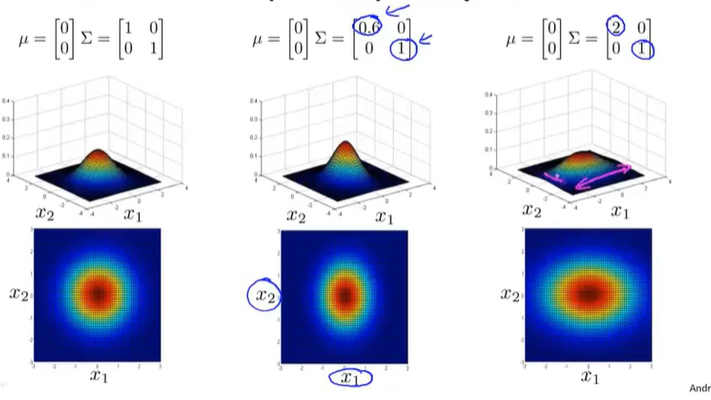
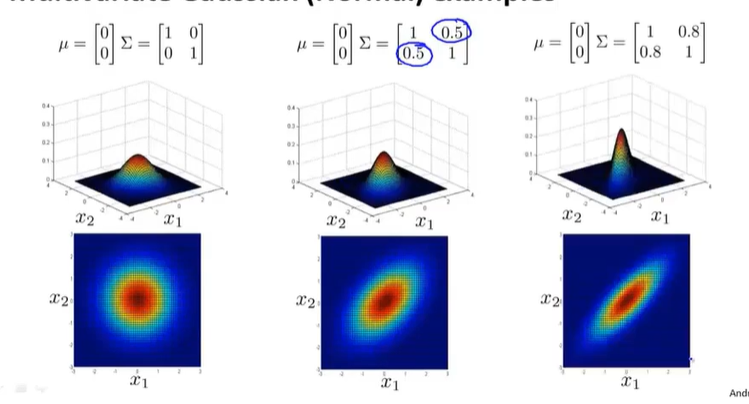
如果是负数的话代表等高线向另一个方向倾斜
μ的影响
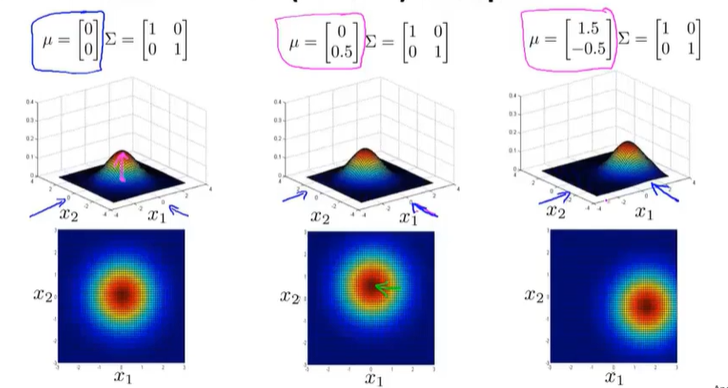
改变分布的中心
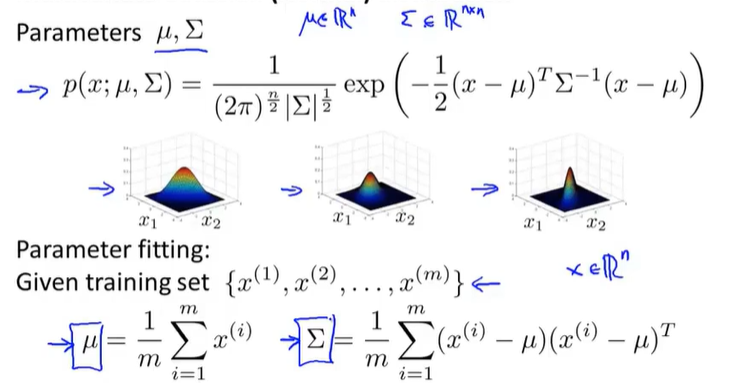
15-8使用多变量高斯分布的异常检测
参数估计后再带入公式
传统的模型,即原来用概率累积的方式,是轴对齐的;原始模型的计算成本比较低;适用于创造不同特征之间组合产生的新的特征;即使样本集数量少也能够使用;
新的模型会自动捕捉特征之间的相关性;计算代价大;且必须保证样本集大于特征否则协方差矩阵不可逆。(m ≥ 10n);协方差矩阵不可逆的原因可能是样本数量太少,或者冗余(即线性相关)的特征太多。
16-1推荐系统的问题规划
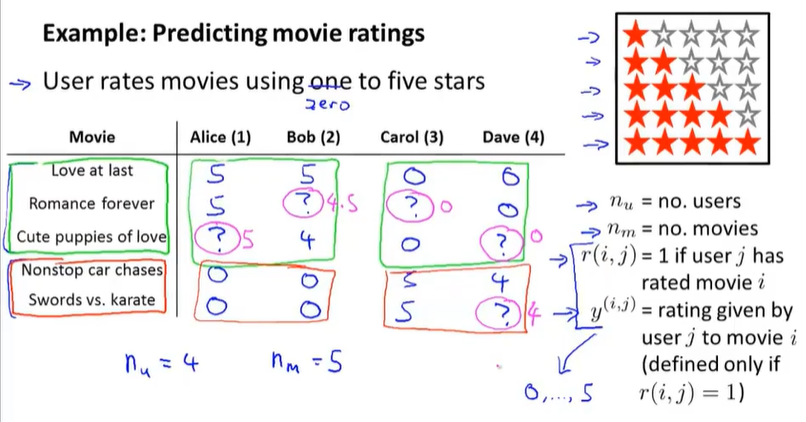
参数介绍
$n_u$表示用户号,$n_m$表示电影标号
$r(i,j)=1$ 表示用户j已经对电影i评过分
$y^{(i,j)}$ 当用户j对电影i评过分时,评分的高低
16-2基于内容的推荐算法
根据特征,对内容进行分类。
求出某个参数theta,根据求出的theta乘上x来预测。
优化目标

梯度下降
