
吴恩达机器学习第14天
16-3协同过滤
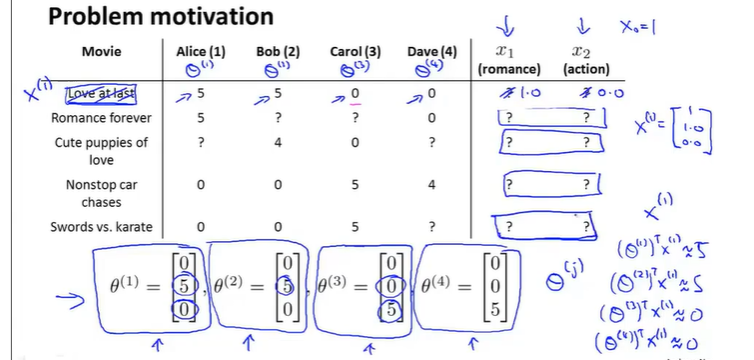
collaborative filtering协同过滤 自行学习特征
从用户获得theta值,借线性方程组来求出X特征
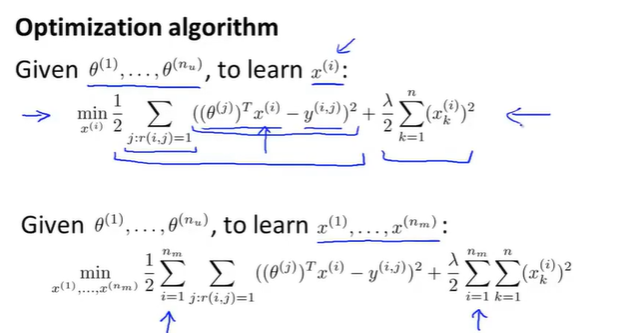
优化算法
设已经知道了用户的偏好theta
则目标函数为
协同过滤
即先给初始化的theta,在学习的过程中修改用户的偏好。(能不能收敛就不清楚了……)
16-4协同过滤算法

1.初始化x和theta(这里的x是不包括x0的)
2.梯度下降
3.根据theta和X估计用户的评分
16-5矢量化-低秩矩阵分解
low rank matrix factorizaton低秩矩阵分解 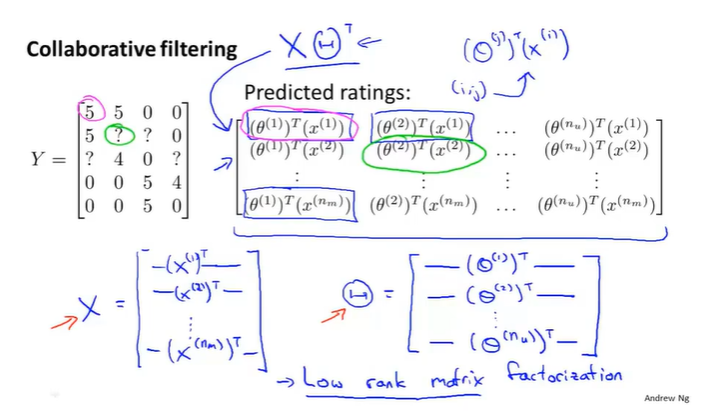
机器可以学习到相关的、但是难以用语言描述的特征
16-6实施细节-均值规范化
设有一个用户没有对电影做出评分,则预测出的偏好都是0,这是不合理的。
均值规范化
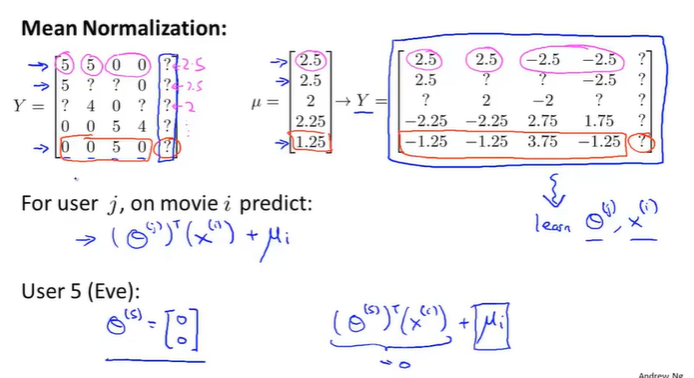
其实就是把均值赋给未评分的用户……简单说就是把最受欢迎的推荐给新用户。
17-1学习大数据集
在进行大数据运算的时候,常常随机选择少量数据进行训练,从学习曲线判断学习效果。
17-2随机梯度下降
Batch gradient descent批量梯度下降
Stochastic gradient descent随机梯度下降 1.随机排序这m个样本
2.对算法过程反复运算
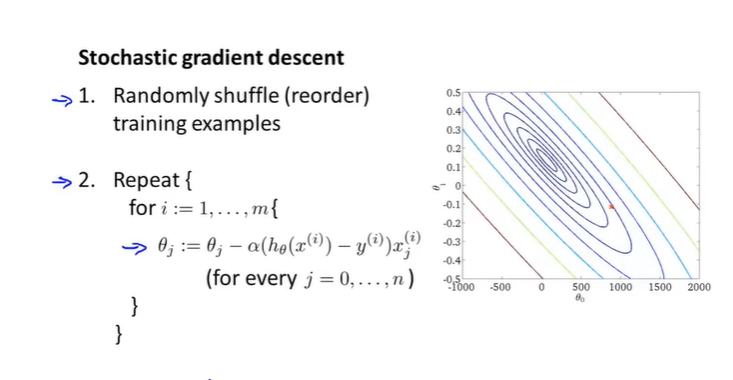
按照说法,就是先让theta对样本一拟合一点,再让其和样本二拟合一点,如此下去,即每次只拟合一个样本。对于外层循环,常常是在1-10之间,取决于样本数量大不大。
17-3Mini-Batch下降
这种梯度下降使用b个样本,常用是[10, 100]
当你有一个合适的向量化,那么Mini-Batch会算的更快,因为有高效的代数运算库。
17-4随机梯度下降的收敛
每内部遍历1000次,就标出代价函数的值。
计算代价函数需要在更新theta之前,看看对新样本的代价函数值。
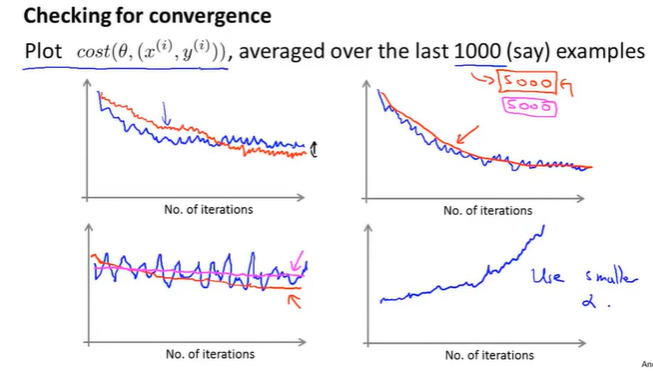
因为之前是让学习率是个常数,可能会导致在随机梯度下降时在最低点附近徘徊,为了取到更好的最低点,会让学习率随着迭代次数的增加而减少。
17-5在线学习
从网络访问的数据流中进行在线学习
个性化推荐、大数据杀熟-。-
17-6减少映射和数据并行
Mapreduce
在多台机器上进行数据处理(并行运算?)
18-1问题描述和OCR流水线
1.文本识别
2.单词分离
3.单词判断
4.单词修正
18-2滑动窗口
行人检测